Skip to content 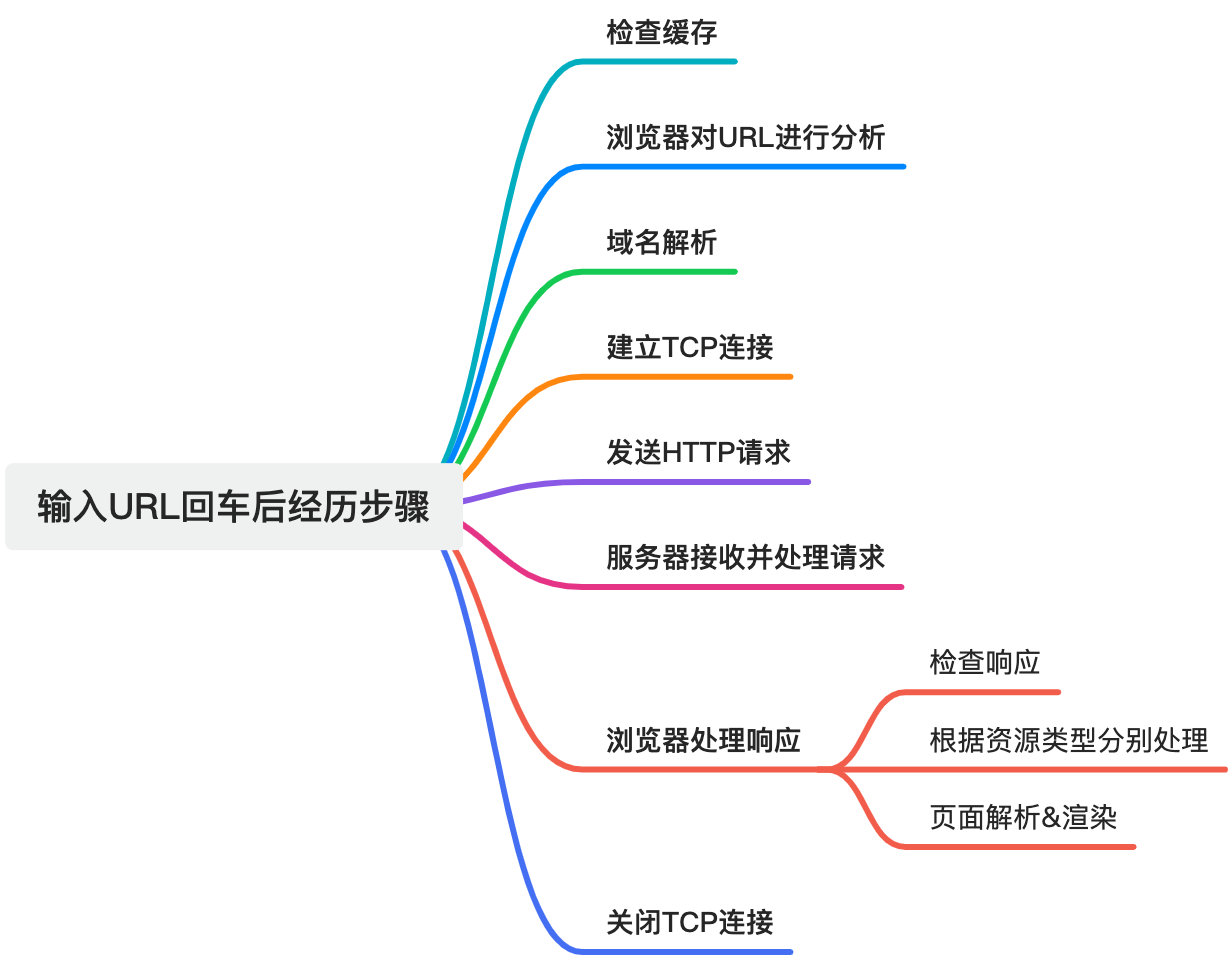
输入URL回车后的全过程
检查缓存
当浏览当浏览器输入一个 URL 时,它会先检查本地缓存,看请求的资源是否已经存在并且还在有效期内。这是为了加速页面加载速度。 具体过程是:
- 浏览器通过哈希 URL 计算出一个唯一的 key,用于查找缓存。
- 在浏览器缓存(内存或本地磁盘)中根据该 key 查找资源。
- 如果找到了缓存资源,并且没有超过该资源的最大缓存有效期,则直接使用缓存。
- 如果没有找到或缓存已过期,则需要发起网络请求,从服务器获取资源。
- 将新获取的资源写入缓存,供下次使用。
这一步主要目的是利用缓存机制加速二次加载,不需要每次都重新获取资源,提高页面性能。
对URL进行分析
当浏览器缓存中没有请求的URL对应的资源时,浏览器会对该URL进行语法解析,主要目的是提取出发起请求所需的关键信息,包括:
- 协议(Protocol):如HTTP、HTTPS、FTP等,标识使用什么应用层协议和该资源的传输方式。
- 域名(Domain name):资源所在服务器的域名地址,如www.example.com。
- 端口(Port):服务器开启的端口号,默认80端口(HTTP)和443端口(HTTPS)。
- 路径(Path):访问资源在服务器上的具体路径与文件名。
- 参数(Parameters):请求的参数,以键值对的形式附在URL路径的后面。
- 锚点(Anchor):页面内部锚链接位置。
通过解析URL字符串,浏览器可以区分出用户想要联系的服务器地址与路径,从而为后续步骤如DNS解析、建立连接做准备。这一步解析主要依据RFC 3986标准来实现,浏览器会逐一检验URL各部分的格式及长度限制,提取所需信息。如果URL不符合语法标准,将无法被浏览器正确解析与处理。 这一步的目的是提取发起网络请求所必须的关键参数,为后续流程做准备。URL的语法规范定义也使得这一解析过程得以标准化。
域名解析
在浏览器解析出URL中的域名后,下一步就是将域名转换成IP地址,这个过程称为域名解析(DNS解析)。
- 浏览器检查本地DNS缓存,看是否已经有解析过这个域名对应的IP地址。
- 如果缓存中没有,浏览器则向操作系统的本地DNS解析器发起域名解析请求。
- 本地DNS解析器也会先在其缓存中查找,如果未命中,则递归地向根DNS服务器发起解析请求。
- 根服务器返回负责这个域的顶级DNS服务器地址。
- 本地解析器向顶级DNS服务器发请求,重复递归查询,直到获取域名的权威DNS服务器。
- 权威DNS服务器持有该域名的记录,将对应的IP地址返回给本地解析器。
- 本地解析器将结果缓存,并返回IP地址给浏览器。
通过这样的递归查询,域名最终被转换成了用于建立连接的IP地址。这个过程遵循DNS协议,以分布式的DNS服务器实现域名与IP地址的映射数据库。 这一步的目的是通过可读的域名取得实际的IP地址,从而进行后续的网络通信。它也实现了域名和IP的解耦,使得网络通信更灵活易用。
TCP连接
获取到目标网站的IP地址后,浏览器会与其建立TCP连接,这个过程称为“三次握手”:
- 客户端向服务器的端口发出连接请求报文,设置SYN=1,随机选择一个初始序列号seq=x。
- 服务器收到syn报文,如果同意连接,则向客户端发回确认报文,确认号ack=x+1,同时也选择一个随机序号seq=y,设置SYN=1。
- 客户端收到确认报文,再向服务器发确认报文,确认号ack=y+1。
完成三次握手,连接建立,客户端与服务器正式开始TCP通信。 三次握手的目的是:
- 确定双方都准备好了通信,避免一方没准备好就被动收到数据。
- 同步双方的序列号,用于后续的数据传输。
- 交换TCP窗口大小信息。
其中,挥手在网络可靠性差的情况下重复发送,直至取得响应或超时放弃。 三次握手需要连接建立前的预先交涉,但可以防止各种异常情况的发生,保证双方准备就绪后再开始传输数据,使得TCP连接可靠。
发送HTTP请求
浏览器在TCP连接建立后会向服务器发送HTTP请求:
- 构造HTTP请求报文:浏览器会根据请求的资源和purpose,决定采用GET,POST还是其他方法,并根据情况构造请求路径,填写HTTP版本等字段。
- 请求行:首先是请求行,包含方法、请求URL和HTTP版本,例如:GET /index.html HTTP/1.1
- 请求头部:然后是各种请求头部,包含请求上下文相关的元信息,如Host, User-Agent, Accept等。
- 请求体:最后是请求体,POST方法时才有,包含要发送的数据。
- 发送请求:浏览器经过TCP连接发送构造的HTTP请求给服务器。
- 等待响应:发送请求后,浏览器等待服务器返回HTTP响应。
- 获取响应:服务器处理请求后,会返回包含响应状态码、响应头部、响应体的HTTP响应内容。
- 解析响应:浏览器接收到响应后,会根据状态码和内容来决定下一步行为。
以上就是浏览器构造HTTP请求并发送给服务器的基本过程,这是浏览器与服务器通信的第一步。
服务器接收并处理请求
服务器处理浏览器发来的HTTP请求并返回响应的详细步骤如下:
- 服务器上的Web服务端软件(如Apache、Nginx等)接收到浏览器请求。
- Web服务器对请求进行解析,提取出请求方法、URL、协议版本等信息。
- 检查请求的语法是否正确,请求资源是否存在。
- 调用相应的后端应用程序或者脚本语言(如PHP、Python等)来生成响应内容。
- 后端程序读取请求资源内容,从文件系统、数据库或通过计算生成。
- Web服务器将响应内容封装到HTTP响应报文。
- 设置状态码(200、404等)表示请求结果。
- 添加响应头,包含内容类型、长度等元信息。
- 把响应报文发送给浏览器。
- 对于动态内容,还可以在响应体中加入Cookies用于会话跟踪。
- 对于POST请求,服务器还要读取并处理请求体中的数据。
- 服务器会缓存静态资源,加速重复请求的响应。
- 根据情况,可能会重定向到其他URL地址。
以上涵盖了服务器从接收请求到发送响应的基本过程,实际上可能还更复杂,涉及权限、数据库、性能优化等处理。
浏览器处理响应
检查响应
浏览器接收到服务器响应后,会按以下步骤处理:
- 检查响应状态码
2XX范围表示成功,常见的有:
- 200 OK - 请求成功
- 206 Partial Content - 断点下载
- 304 Not Modified - 资源未修改,直接使用缓存
3XX范围表示重定向,Location头指向新地址:
- 301 Moved Permanently - 永久重定向
- 302 Found - 临时重定向
4XX客户端错误,如:
- 400 Bad Request - 请求语法错误
- 404 Not Found - 找不到资源
- 403 Forbidden - 没有权限
5XX服务器错误:
- 500 Internal Server Error - 服务器内部错误
- 503 Service Unavailable - 服务不可用
- 检查响应头信息
解析响应头,查看内容长度、类型、编码方式等元信息。
- 根据状态码决定下一步行为
如果是成功2XX代码,则继续处理响应体。3XX代码则重新请求重定向地址。4XX和5XX为错误码时要给用户错误提示。
- 读取并处理响应体
成功响应后,浏览器会根据响应头给定的内容类型解析响应体,并展示内容或者保存文件等。 这样浏览器就可以根据服务器返回的HTTP响应状态码和内容来决定下一步的处理,完成请求资源的获取。
根据资源类型分别处理
如果服务器返回的响应状态码表示正常(2XX),浏览器会根据响应头中的内容类型(Content-Type)来解析响应体并进行处理,常见的有:
- text/html - HTML文档
- 浏览器会解析HTML内容,构建DOM树,加载解析过程中遇到的资源
- image/png、image/jpeg等 - 图片
- 浏览器会解析出图片内容,并显示在页面中
- video/mp4等 - 视频文件
- 浏览器会调用视频播放器开始播放
- application/javascript - Javascript脚本
- 浏览器会执行脚本来修改DOM和行为
- text/css - CSS样式表
- 浏览器会解析CSS来渲染页面
- application/json - JSON数据
- 浏览器会解析JSON字符串并触发相应callback
- text/plain - 文本内容
- 浏览器会直接显示文本
- application/octet-stream - 二进制文件
- 浏览器会下载文件并存储在本地
不同类型的响应,浏览器会有不同的解析方式和处理流程,最大程度地恢复资源的原始内容和行为。
页面解析&渲染
这里主要涉及的是浏览器响应成功后获取到HTML文档后的步骤:
- 获取HTML文档:从响应内容中获取到要解析的HTML文档
- 解析HTML构建DOM树
- 浏览器使用解析器(parser)读取HTML代码,分割成标记(tag)、文本、注释等标记化(tokenized)后的 tokens。
- 根据HTML语法构建DOM节点树。遇到开始标签创建元素节点,遇到文本创建文本节点,注释也会创建节点。
- 每个节点是一个对象,保存了标签名、属性、内容等信息。节点之间根据嵌套关系建立父子关系。
- 其中
<html>为根节点,<head>和<body>为子节点。其他各级节点也逐步添加为树结构。 - HTML的attribute会被解析为节点的属性。类似id、class等。
- 构建完成后形成一颗以HTML标签为节点的DOM树。
- 这个树描述了HTML文档的节点关系和内容信息,是后续CSS和JS可以访问的表示形式。
- 浏览器使用DOM API可以访问或修改DOM节点树的内容。
- 解析CSS构建CSSOM树
- 浏览器使用CSS解析器读取CSS代码,按照CSS语法规则分割为标记化的tokens。
- 浏览器会根据CSS规则生成对应样式规则(style rule)的节点对象。
- 每个节点包含了css选择器和对应声明的样式信息。
- 节点之间根据CSS的继承、层叠等规则建立树结构关系。
- 根节点是代表全局样式信息的根规则集(Root Style Sheet)。
- 每个规则下面连接具有对应选择器的规则节点。
- 构建完成后形成CSS对象模型(CSSOM)树结构。
- 树结构中每个节点代表一个可复用的CSS声明对象。
- 通过CSSOM API可以访问读取节点的样式信息。
- 构建Render树
- 浏览器将DOM树和CSSOM树结合,生成一个Render树(Render Tree)。
- Render树中的每个节点称为RenderObject,包含内容、样式和布局信息。
- 对于DOM上不影响渲染的节点,如script、meta,在Render树中不会创建对应的RenderObject。
- 对于每个可见的DOM节点,根据匹配的CSS规则,生成带有样式信息的RenderObject。
- 如果一个DOM节点被多个规则匹配,则根据CSS的层叠、继承、优先级等计算出一个综合样式。
- Render树的根节点是代表视窗的RenderObject。
- 子节点层层添加,形成代表页面结构与样式信息的Render树。
- Render树准确描述了页面的视觉表示与布局信息,用于下一步的布局和绘制。
- 当DOM或CSSOM更新时,可以增量更新Render树,无需全部重新构建。
- 布局(Layout)
- 从Render树的Root节点开始遍历所有对象,计算布局。
- 根据RenderObject的类型、属性,确定其显示模式,如块状或内联。
- 对块元素,计算其精确的位置、宽高等几何信息。
- 对内联元素,计算其在当前行内的定位。
- 父节点会影响子节点的布局,布局受包含块大小的影响。
- absolut positioning脱离普通流,根据offset parent定位。
- 浮动元素也会脱离普通流,但会影响兄弟元素布局。
- 创建行盒、块盒等箱模型表示内容区域。确定padding、margin、border大小。
- 计算滚动溢出、自动换行等,移动或裁剪元素。
- 布局完成后,每个RenderObject都确定了页面中的坐标位置。
- 绘制(Painting)
- 根据Render树和Layout结果遍历所有RenderObject。
- 根据节点类型和样式信息,绘制不同的UI内容,如文本、颜色、图像等。
- 对文本内容,根据font样式绘制文字图形。
- 对图片和视频,根据src绘制图像位图。
- 对颜色和背景,填充绘制颜色矩形区域。
- 绘制完成后,内容从逻辑坐标映射到设备坐标(屏幕像素)。
- 由上至下,由左至右顺序绘制,遵循层叠顺序。
- 创建堆叠上下文(Stacking Contexts)表示层叠和z轴次序。
- 绘制过程遵循各种CSS属性,如透明度、变形等效果。
- 使用GPU加速绘制提高性能。
- 绘制内容到设备缓冲区(Framebuffer),并显示在屏幕上。
- 合成(Compositing)
- 浏览器可能使用多个层(Layer)来分别绘制页面中的不同部分,以提高效率。
- 这些层需要按照正确顺序叠加到一起,以表示 DOM 层叠顺序。
- 根据堆叠上下文(Stacking Contexts)的 z-index 值决定层的堆叠顺序。
- 合成步骤会将这些层合并到最终的图层组合中。
- 如果某层需要透明效果,该图层需要与下层进行混合。
- 使用GPU上的复合器(Compositor)来进行图层的合成。
- 将合成的位图最终绘制输出到显示环节。
- 合成步骤还会考虑页面的动画、转换、阴影等效果。
- 如果内容变更,只需要重新绘制变更的层,而不需要全部重绘。
- 更新渲染树和重绘
- JS或用户交互可能会修改DOM树,也可能会变更CSS样式。
- 浏览器会监听这些变化,比如元素内容改变、样式表修改等。
- 当发生变化时,需要重新构建渲染树来反映更新后的状态。
- 对于影响渲染的DOM更改,需要同步更新渲染树对应的内容和样式信息。
- 如果仅仅是CSS规则变更,可以只更新渲染树中的样式信息。
- 对于新增或删除DOM节点,需要插入或删除对应渲染对象。
- 构建好新的渲染树后,进行后续的布局和绘制流程。
- 绘制时可能只需要重绘受变更影响的部分渲染树分支。
- 浏览器会尽量只重新绘制变更的部分,以提高效率。
- 完成后在界面上显示新的更新渲染结果。
以上是页面渲染的基本流程。
关闭TCP连接
浏览器与服务器建立TCP连接后,当HTTP请求响应全部完成时,它们会四次挥手关闭连接:
- 浏览器发送一个FIN标志位请求,表示客户端没有数据发送了,要关闭发送方向。
- 服务器接收到FIN后,发送一个ACK确认包,确认序号为收到序号+1。
- 服务器发送自己的FIN,表示服务端没有数据发送了,关闭发送方向。
- 浏览器收到服务器的FIN后,浏览器发送ACK确认包,确认序号再次+1。
这样四次挥手完成后,浏览器和服务器都没有数据要发送了,连接关闭。 关闭连接的目的是:
- 通知对方我已经没有数据要发送了。
- 确认对方知道我要关闭连接了。
- 同意对方也可以关闭连接了。
- 对方确认知道我要关闭连接。
四次挥手的作用是保证双方都没有数据在网络中传输时,才可以安全关闭连接,防止数据丢失。 只有当浏览器和服务器都没有需要TCP连接进行传输的数据时,才可以进行四次挥手关闭连接,节省系统资源。